I have been watching a number of the NVIDIA GTC (GPU Technology Conference) talks on this week. I have mainly been watching talks related to Omniverse (their 3D rendering and simulation software). I was interested in automation of simple animated videos, such as how much can AI (such as large language models) reduce the effort to create simple stories. Not Pixar level quality, more like cheap cartoons. I just watched a presentation from Vincent Vanhoucke (Senior Director of Robotics, Google DeepMind) titled “Robotics in the Age of Generative AI”. Fascinating stuff! Can robotics be used to control the animated characters?

From what I saw, yes! So I decided to also attend the following session “Breathing Life into Disney’s Robotic Characters with Depp Reinforcement Learning”. Perfecto! (And very cute!) These are the robots that were in Jensen’s keynote presentation (at the end).
The following is my summary of these two sessions, from the point of view of using large language models to control 3D animated characters to record them as actors (not control real robots). Hopefully the videos will be online later with a lot more detail if you are interested.
TL;DR: Interesting stuff, but not a short term solution for individuals like me.
Robotics in the Age of Generative AI
The first talk from Google described their history with robotics, how the field a few years ago (simplified) was around planning (to achieve goals), actuation, and perception.
- Planning is deciding what was wanted to be done (a semantic action, like “pick up the bottle”).
- Actuation is making the robot move (turn on servo #3 at 75% speed).
- Perception is getting environmental feedback so the robot can cope with a changing environment.
The above are closely linked, with planning and perception influencing actuation.
So what has changed is the introduction of generative AI, and large language models (LLMs, like ChatGPT) in particular. It turns out it opens up new approaches to tackle the robotics problem.
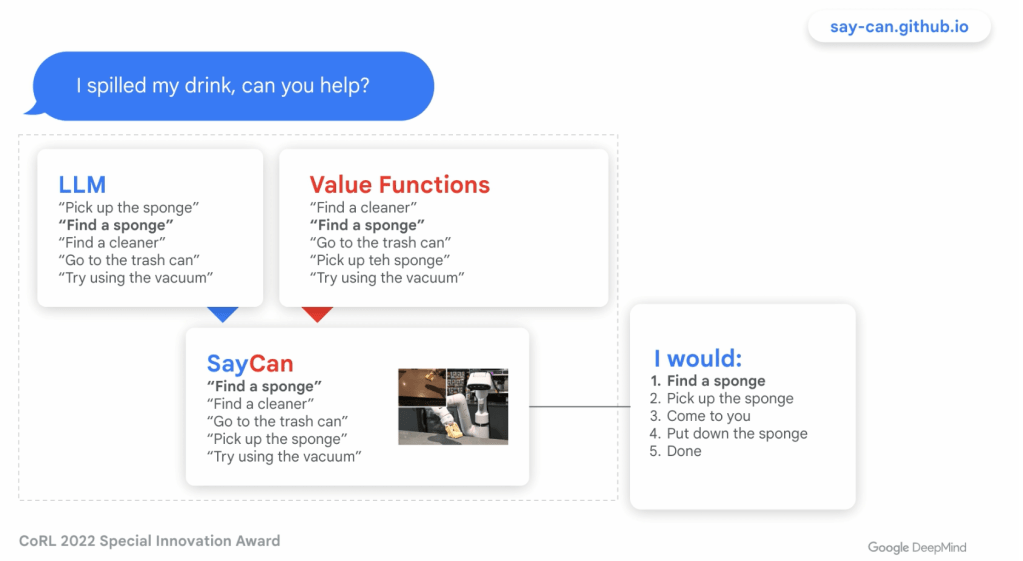
The first step was to try using the LLM to describe the actions needed to perform a task in “Robotese” (a limited version of English that the actuator can understand). A cool benefit is it is easier for humans to understand.
Note that it can also respond showing its thinking along the way, helping with debugging.
Sometimes it would come up with (hallucinate) actuator commands that did not exist. What now? One approach was to ask the LLM how to perform those commands. It would define action sequences that it could add to the library of known actions. (This can fail at times of course, but it was surprisingly effective. I heard of another paper doing a similar thing. Don’t get the language model to understand everything – give it a starting library of known actions, then let it extend the library so that once it works out how to do something once, it can refer to that action by name from now on.)
For example, in the following there is no “stack_objects()” method defined. So the LLM was asked to write the code for that as well.

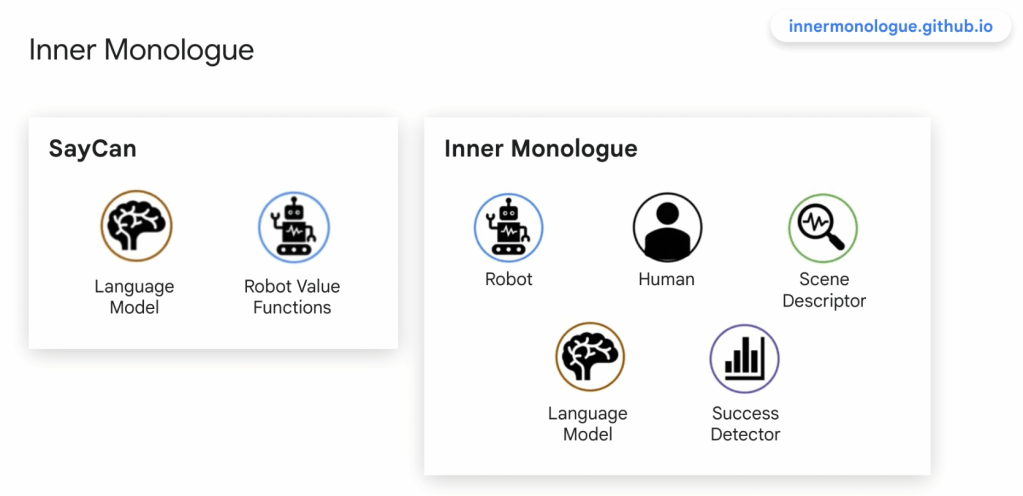
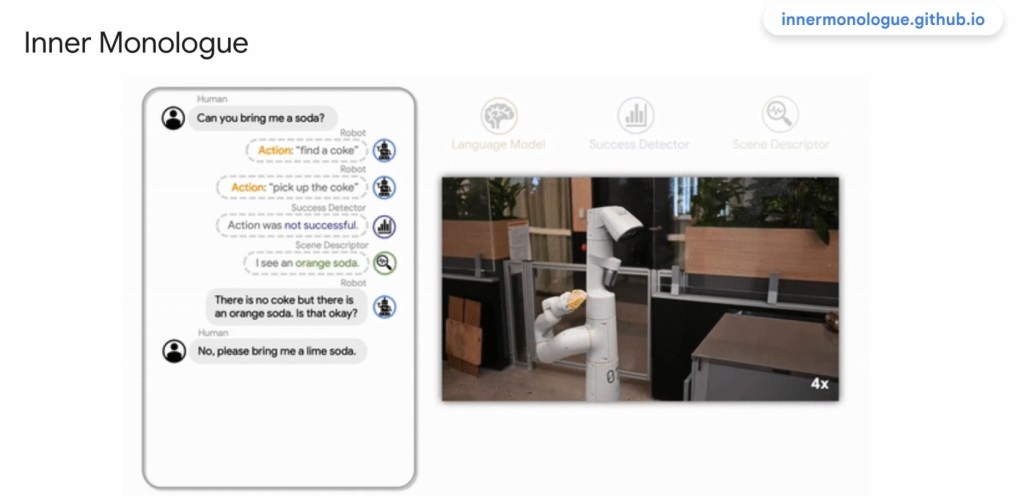
They have it so you can teach the model as you go. E.g., “Give me a high 5”. “I don’t know how.” “Here is how. Raise your hand. (Robot lifts hand.) Higher. Now open your hand. That’s right. Now move your hand forwards and back quickly, like you are clapping your hands together, but you are clapping my hand. You will do that to my hand. That is a high 5.” Actions get added to the library of known actions, but it was taught using English. See the following diagram for an real example interaction.
Note: While it works out code, the robot performs the action so the human can provide immediate feedback and instructions until it is correct.

The robot re-plans frequently as the environment can change after the original plan was made. Maybe a new object moves in front of the robot, or for my interest in animation, maybe one character reacts to actions performed by other characters.
They include vision systems to recognize what is going on in a camera’s viewport. A scene image can be turned back into text describing the scene. This is where the recent advancements in multi-modal LLMs are interesting. They can feed in text *and* images from the camera to work out what to do next, merging different steps.


The multi-modal models are slower, running about 3 computations per second. But this is generally sufficient to plan out actions and take into account environmental changes.
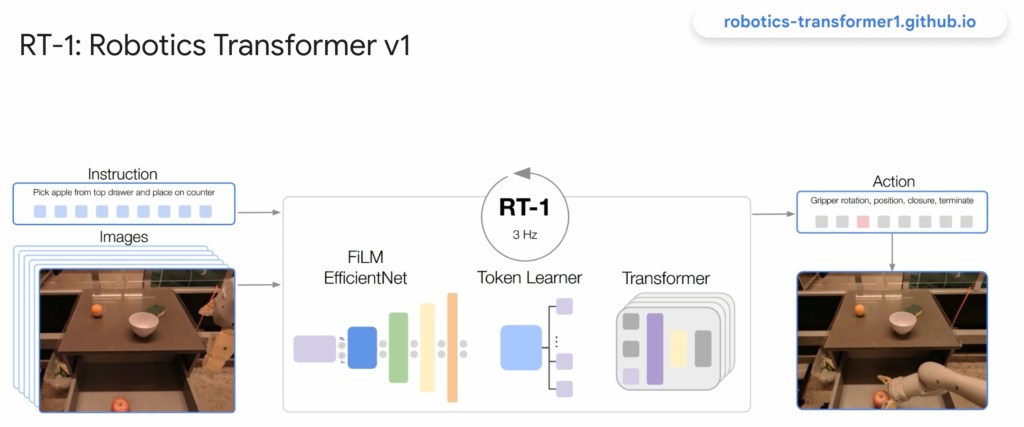
Version 2 has been working well so far (but still research).

The end result has been using multi-modal models (ones that can text and images as inputs) are working well. Humans can instruct it to teach it new things. Humans can see how the robot is thinking to help with debugging. Accuracy of results have been improving. But overall it is still research. For example, language models are not great at math (including 3D transformation computations). Maybe LLMs will solve this, or maybe you just need to describe objectives as “text” rather than precise math.
Another aspect was putting controls in place. You want to train the models to do valid things. For example, don’t permit an arm rotation that goes through the body, and apply speed limits to movements imposed by the servo motors. So there is training required so it understands what it can and cannot do. To help, the robot can use internal simulation models to see the result of a planned action before doing the action in real life, as a form of safety check.
Oh, and the presentation had a team picture. Yikes! I might not try this all at home! 😉

I had not expected that session to be so interesting to me, which raised my interest in the following session.
Breathing Life into Disney’s Robotic Characters with Deep Reinforcement Learning

In the case of Disney, they are interested in robotics in a way closer to my personal goal of simplifying animation. The goal is not to create a single robot that can perform many different actions (supporting mass production), but rather create believable individual characters with personality. The want the robots to “act”. Their robots are also custom (not general purpose), one per character. Examples included an Ironman robot to a star wars robot.

For the star wars robots, they were exploring using them at theme parks. The robots are controlled by a remote control with dual joysticks and lots of buttons. One joystick controlled movement (walk), the other controlled the head. There are also a series of animation clips programmed in. So the robots do not have to independently cope with new novel environments. In fact, they have no camera vision providing feedback! (Just internal sensors to know what is up.) A human is deciding where they move to and what they do.
So is this still robotics? Yes! The movement joystick sets a direction, but the robot then has to know how to walk and balance on a variety of surfaces. (Side note: the robots use NVIDIA Jetson technology internally, hardware designed for such use cases.)

The shell of the robot is 3D printed, which allows them to make more rapid iterations and adjustments. They don’t need to make thousands of the same robot. In fact, it is more desirable to make each robot personalized.
So how did AI fit into the story? In three ways.
First, they had procedural animation created by a human. This is so the character has personality (e.g. a cute little bobbing shuffle). But the animation does not take into account physics or how the motors on the robot work. And the character needs to walk forwards and backwards, turn, run (walk faster), side step, and more. So they train a model by feeding commands into procedural animation code that generates the desired state, then also feed the same commands into more detailed simulation software. The results are compared, and the model is trained to achieve the desired goals. (A feedback loop responds whether then model replicated the movements well or not.)

After procedural animation is under control (e.g., walk cycles), animation clips are added. Again, these are created by a human animator. For the star wars robot they are a series of “cute” actions, head bobs, whistle sounds, look around, look sad, and so on. Again, the animation clip is compared to a neural network to learn how to turn the animation clip into motor controls.
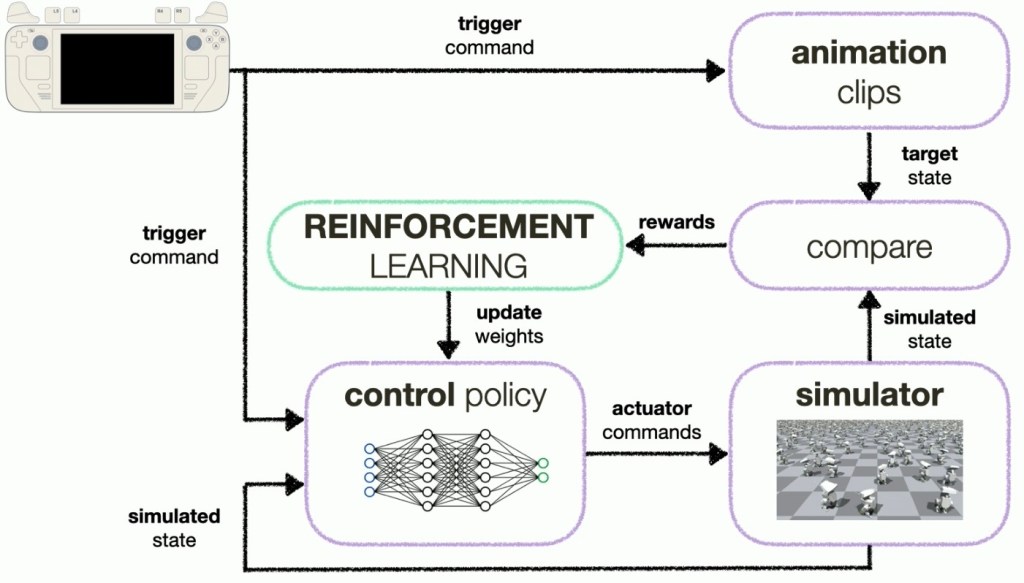
A third aspect is kinematics. The robot has mass, there is gravity, the center of gravity moves as the robots walks or moves its head, and people might bump into the robot. How to make sure it behaves correctly and avoids falling over. This is achieved by applying random bumps and movements to the robot and training it to recover.
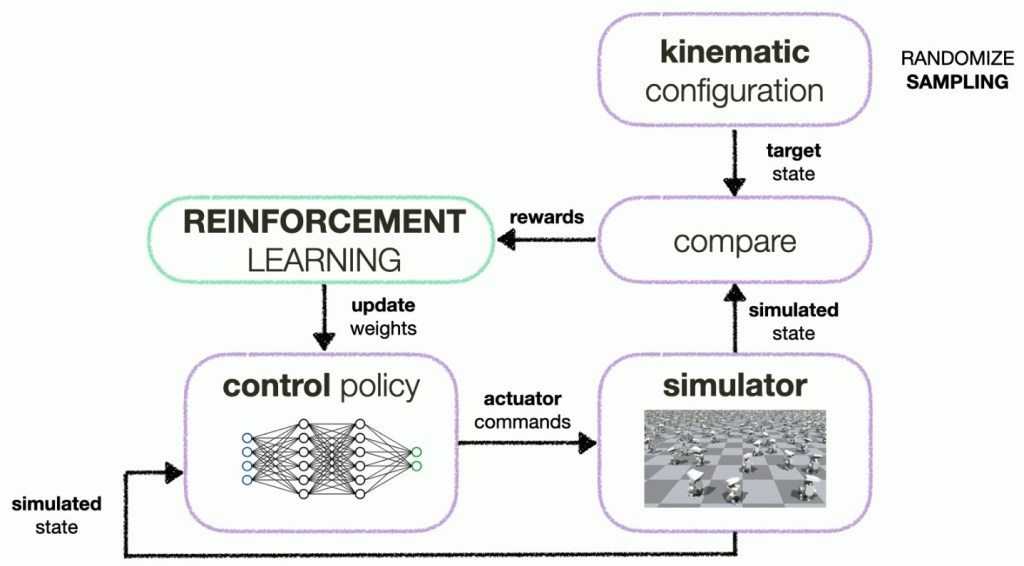
So how did they achieve all of this? Using NVIDIA Isaac SIM! (What did you expect? Its an NVIDIA conference!) It is a robotic simulation and training system leveraging NVIDIA Omniverse for rendering. By using simulation software, they were able to perform years of training in all sorts of environments in days. They could create many different types of terrain, different friction for the ground, throw objects at the robot, and so on. The simulation software let the robot learn how to cope with them all by trying things and then getting feedback of what worked well and what failed.
There were many aspects to this. For example, animation clips could be triggered at any time (even if a previous clip was still running), so the system was trained also how to blend animation clips – to start a new animation from any existing pose. It was trained on many different combinations and positions to ensure the robot reacted correctly (in simulation software so a physical robot was not required to repeat such tasks). Real robots are limited to the speed of real-world robot movements instead of simulation where the robot can be artificially sped up with multiple copies running in parallel.
So suddenly, robotics simulation is a lot more interesting to me. Can I train up characters to “act” in unique, individual ways? Can I train each character personalized mannerisms? Make them walk differently, teach them different idle animations or ways to express emotions? When angry, does the character fold their arms or look downwards with fists clenched? And can I teach the characters to avoid furniture in a scene. For example, when standing up from a chair at a table, should the chair be pushed backwards first. That needs concepts like grippers (the hands) and physics. The goal is to “direct” my robotic actors using higher level instructions, without having to repeat mannerisms per shot. Fun!
GR00T!
This also brings me to another NVIDIA announcement, project GR00T!, a general purpose foundation model for humanoid robots. I don’t know much about it yet, but my actors are humanoid, so I will be interested to see if this could be used to speed up the above process.
Conclusion
I am not sure yet if robotics will be useful in character animation, but it is at least a good excuse to dive into the robotics support and learn more!
