I have been exploring using Generative AI (LLMs specifically) to assist with going from a screenplay to an animated video, learning about relevant technologies along the way. (No, I have not got that far, but it’s fun trying and learning!) For example, at the recent GTC 2024 there were some interesting sessions on Robotics from Google and Disney. It reminded me of an older paper on Voyager – getting AI to play Minecraft. The GTC videos are just being published now, so I also just got to view Jim Fan’s presentation on “Generally Capable Agents in Open-Ended Worlds“, which also mentioned Voyager. This blog summarizes the highlights from this work that interest me.

My interest is in animating 3D characters for creation of a video, without being an animation expert. I am not trying to generate high quality animation like a Pixar movie (although that would be nice!), but rather simplify creation of simple animation more like a cartoon series. But the animation should meet a minimum level of quality. The visuals of animation is part of its appeal and the physical motion of a character can convey a lot of emotion.
So my personal goal is to create an animated series (on YouTube) where I can tell multiple short stories with the same characters — a series. That means it is worthwhile investing more time creating a set of assets and tools as I will reuse them. (Well, to be honest, exploring the tools is probably more fun for me than creating the content!)
How time consuming is creating good quality animation today?
Good quality animation is VERY time consuming. There are techniques like motion capture allowing capturing human actor movements instead of defining curves for each joint movement, but it is still time consuming. Even with motion capture, you still need to “clean” the animation to fix little capture errors. And you need a big space, good lighting, cameras or other motion capture equipment to do the capture. There is real overhead.
In video games, they often use libraries of movements like “walk”, “jog”, “run”, “sit”, “stand up”, “stand idle”, and “punch”. Characters controlled by the player and NPCs (non-player characters) can reuse these clips, chained together. When walking, the same animation is looped for each step. It never changes. Multiple characters may also use the same animation clips. This can result in a feeling of “sameness” in a game.
In high quality animation, every movement on screen is planned out. Each movement and pose, is tuned to support the emotion of the scene. These are often exaggerated versions of real life.


Individual poses by chuunin7 on DeviantArt https://www.deviantart.com/chuunin7/art/Gesture-Emotions-1-205796534
Tools like Cascadeur are leveraging AI and physics to help animators. In Cascadeur, physics is used to flesh out between keyframes, taking into account physics. It can make complex sequences of actions (like in a fight scene) more realistic.
Personally, I don’t mind posing characters or recording motion capture, but it is not what interests me. I want to spend more time on telling the story itself. I want to use AI or similar to reduce (but not necessarily eliminate) animation effort. I don’t want the same animation for every character. I want the animation to emphasize the character’s personality as much as possible. Since I am doing a series, I am happy to build up a library for characters so I can reuse in later episodes. So my interest is in some degree of personalized animation for characters, but with lower manual overheads. (Hey, I can dream, right?)
There are a number of text-to-motion tools (such as SayMotion and Mootion) appearing, giving me hope of good solutions in the coming years. The tools I have seen so far however are hard to control. I don’t want arbitrary movements – I want the motions to support the story I am trying to tell. This is why the robotics sessions caught my attention. Disney are animating robots with individual personality. It is all about expressing emotion. But there is reusable technology underlying the robots.
Note: Mayaenite on the Omniverse Discord posted an impressive video that leveraged Motorica AI Motion Generation, generating 10 second animation clips then linking them together into a longer video. Nice work!
Robotics
The Google presentation at GTC described their journey over recent years. They summarized the robotics challenge around planning, actuation, and perception.
- Planning breaks down high level instructions into finer grain steps. A command such as “Get a soda” might be broken down into “Move to soda machine”, “Select favorite soda of user from available choices”, “Push button to get Soda”, “Move to user”.
- Actuation is the process of performing the finer grain steps. Note that actions such as “Move to soda machine” could be broken down into smaller steps such as “turn left 90 degrees”, “move forward 3 feet”, and so on. Planning needs to know what actions are understood by actuation.
- Perception is understanding the environment to sufficient level to feed back into actuation to ensure success. For example, look at the soda machine to work out which flavors are currently in stock.
One of the aspects worth expanding on is the idea of recursive planning. Ask a LLM to plan out how to perform a requested goal in terms of actions. But rather than have a fixed set of built in actions, allow a library to be built up. If the LLM generates an action plan that involves an action not currently defined, ask the LLM to define how to perform that action and put the result into the library for use next time. If it cannot work it out automatically, get a human to explain (via a chat interface) how to perform the action.
For example, a plan may end up with “put soda can in front of user” and then “ask for a tip”. If the robot does not know how to “ask for a tip”, then a human may describe what the robot should do. “To ask for a tip, put one hand on your hip in an impatient pose and put the other hand out towards the user with palm up. When someone puts money in your hand, put that in your pocket. Give up after 10 minutes if no money is provided.”
Voyager
The reason I find the Voyager paper interesting is it demonstrates the effectiveness of the above. It has a skill library that steps are added to as individual goals are worked out while playing Minecraft.
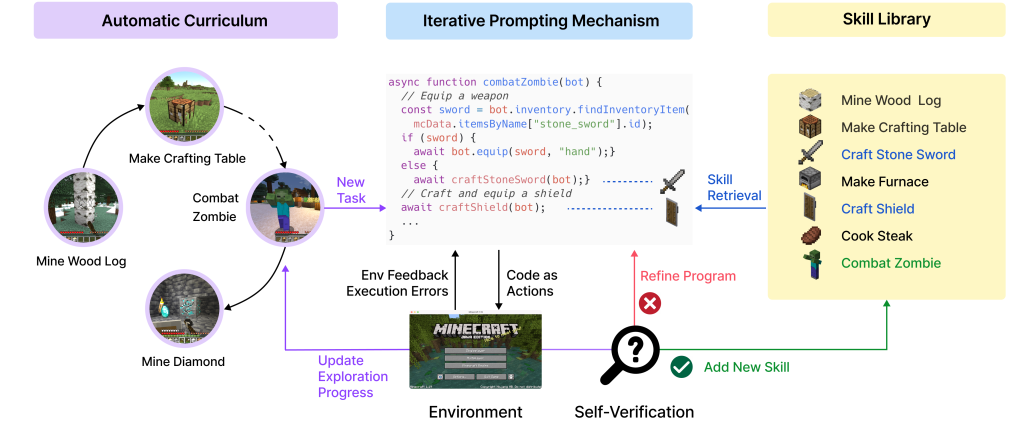
The “Automatic Curriculum” is the planning phase. It uses JavaScript as the action language (many LLMs are already trained to write code in JavaScript). References to the action library are function calls. If the function is not found, new code is generated and added to the skill library. If the code fails to work, it is regenerated or improved via chat prompts. The LLM is also used to “summarize the code” which generates a textual description of the skill, which can then be used in semantic searches by the planner to find potentially relevant skills for the actions needed.
There are lots of cool examples in the Voyager paper, such as iterative prompting. If the code fails, ask the LLM to fix it from the code and error message.
Jim Fan
Just as I was about to post this blog, Jim Fan‘s GTC talk was published.
The focus of the talk is also on robotics, talking about multiple projects (including Voyager) in the space and how they have pushed different boundaries. He described a new initiative, the GEAR Lab (Generalist Embodied Agent Research). I am personally also keeping an eye out for Project Gr00t from NVIDIA, a generalized humanoid robotics model. It sounds early in its development, but might be useful in the coming years.
Screenplay to Actions
Coming back to my goal of a human written screenplay as the starting point, I want to convert whatever level of detail is provided by the writer into actions. The writer in my case is also the director. So I want to start with location descriptions to pick the set to use, then set the initial position of characters in the scene, then generate action lists to make them move. This corresponds to the planning stage above.
I also want to get individual personality per character. One of the things I was interested in with the Disney work is where does personality fit in? Does personality affect the overall planning of actions? Or is it the poses? Or is it part of the betweening for keyframes? In my case, I am after supporting humans who wrote a screenplay. I am not trying to generate stories with AI, I am trying to help humans tell stories that matter to them. So I am not trying to decide if a one character wants to tease another character — that is the writer’s decision. I am more interested in the body language of the character visually support the “teasing” attitude the character should have, consistent with the character’s personality.
In the Disney example, AI was used to train the robots to walk (in Omniverse Isaac SIM). There was no personality here, just “make it work reliably”. They added personality via animation clips (head tilts, lights, sound effects). These were then combined into a final result.
This, by the way, is an example of an “agent architecture”. Create AI agents to do one job well, whether planning or coding up a new skill, and get them to communicate and coordinate to solve bigger problems. This sounds familiar with how I understand the human brain works. One part of the brain focuses on speech, another on motion, another on planning, and so forth.
Conclusions
It feels like the space of text to motion is continue to push forwards. There are some text to motion generation products around, but I want to chain them into a sequence to support a story. That does not quite feel “there” yet. While I am interested in animation for storytelling, I think a greater industry thrust is on robotics. There is more money to be made there with unsolved problems.
