This is a first post in a new thread looking at using machine learning to speed up my process of assembling camera shots in an animated cartoon series (the series I would be working on if I did not get distracted all the time by shiny new technology to learn… ahem!). Can I speed up my personal workflow by writing a screenplay as text, and have the computer do the boring repetitive steps for animating a new shot so I can focus on the creative parts.
This post introduces the basics of machine learning, introducing concepts and trying to take away a bit of the mystery. Then I introduce the problem I am going to tackle with it. Later posts will tackle incremental challenges such as identifying which characters are in a shot or selecting animation clips based on the textual description, based on previous episodes I have completed. (This series is not going to look at generative AI for creating images for videos.)
What is Artificial Intelligence and Machine Learning?
Here is my take: Artificial Intelligence (AI) is about getting a computer to make decisions that a human would look at and say “oh, that was an intelligent decision”. Machine Learning (ML) one approach to achieve this goal. A common machine learning technique is to show a computer a set of input data and correct answers (output data) and tell it “when you see similar input data, generate the same sort of answers”. The machine is meant to “learn” from the set of training data, and then predict answers when it sees similar input data later.
The reason I am explaining this for those not familiar with AI is to show that what is happening is the computer does not “understand” the problems like we do as humans. Computers can process numbers very fast and spot patterns in numbers, making predictions based on the given inputs. But computers rely on humans to turn problems into ways machine learning can understand, and they have to pick the right algorithm to use as different approaches are suitable for different situations. This often involves trying a number of different approaches, or coming up with clever new approaches.
Let’s start with some basic concepts.
Linear Regression
Jay Alammar had some great videos introducing AI and ML which I am going to borrow from a bit here. Computers like dealing with numbers. So to ask it a question, you need to turn your question into numbers. Let’s say you have a problem of predicting how much money a group of people will spend when they enter your ice cream shop. You watch for a while and you come up with the following observations:
Group Size Money Spent
1 $10
2 $20
4 $40
5 $50
If I asked you how much money will be spent if a group of 3 people turn up, as a human, you would probably guess $30. It looks like money spent is $10 per person. Most people would be pretty confident in that prediction (I certainly would!).
When you get into machine learning, answers may come with a probability attached. The “confidence” in the answer being $30 above would be very high. You can solve this problem using a linear regression approach – you fit a straight line through the data points, and discover the line is y = 10 x.
But what if the group size was 1,000? Do you think $10,000 would be spent? In real life, you probably would not be able to fit 1,000 people in the store, you might run out of ice cream to sell, and some people might just get tired of waiting and leave. A group size of 1,000 should reduce your confidence in the result because the input data is so different to what has been seen before.
What if the input data is not as clean as the above example?
Group Size Money Spent
1 $9
2 $21
4 $39
5 $51
You would probably still be fairly confident they will spend close to $30. The more the numbers vary, the less confident you would be in the answer. So the confidence or probability an answer is correct can be as important as the answer itself.
Is linear regression good for all problems? No. Consider flavors of ice cream. You have 10 flavors, so you give them a number from 1 to 10. What is the most likely flavor of ice cream a group of three people will buy. Getting an answer or 3.7 (the average of a sample data set) is meaningless. The computer wanted numbers, but they are actually discrete, unrelated values. There is no relationship between the numbers on an x-axis. So you need different approaches beyond linear regression.
Neural Networks
How could you improve the estimate of money spent in real life? Time of day might change how much is spent, the age of group members, the temperature outside, the day of the week, and so on. These are often referred to as “features”. Adding these additional columns (features) might improve the prediction of how much money will be spent. Again, humans have to pick the features to make available to the algorithm.
And why just generate one output? Rather than just money spent, you might like to know how much of each flavor is sold. This may help you order the right amount of each ice cream flavor in advance to make sure you don’t run out. So now there are multiple inputs and multiple outputs.
The ideal of neural networks for machine learning came from examining how human brains work inside. In a nutshell, the idea is to have lots and lots of simple nodes (neurons) that have connections to other nodes with weights attached to each of the inputs. The way nodes are interconnected matters, as does the number of nodes. Especially important is neural networks can have multiple inputs and generate multiple outputs.
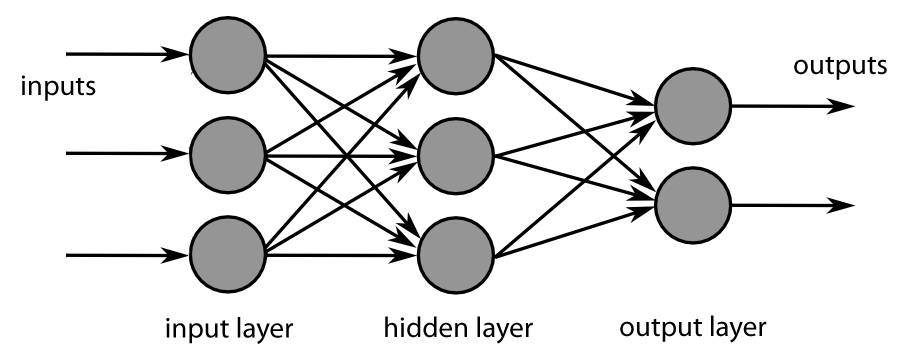
Once you have a network, there are clever approaches to train the network. Training the network works out the right weights to use for different interconnections inside the network. After that you can feed in similar inputs and get predictions on the outputs. It works surprisingly well, especially as the size of the network increases.
So in the ice cream store example, we could have inputs of all the features mentioned above (size of group, time of day, day of week, outside temperature, etc) and outputs of how much of each flavor of ice cream will be consumed and the total money spent. Neural networks have turned out to be a really useful tool in machine learning.
Clustering and Segmentation
What if you want to train your serving staff to make better recommendations to people coming into the store. Can you work out from past sales is there a relationship between say age and preferred flavor. Or time of day. Maybe as you collect an order your staff can enter the current selections and the computer can recommend other flavors they may like. Or, maybe you want to group flavors based on categories like “sweet, subtle, and unexpected”. How do you turn that problem into numbers?
To achieve such goals you need to collect data such as previous sales transactions and how many of each product in your catalog you sold. That is, if you have 20 flavors of ice cream, you might have 20 inputs for the number of scoops of each flavor, in addition to the time of day, day of week, etc as other inputs. Then when you start knowing a new order, you can predict what the customer may like based on what other people have ordered before. Want to get fancy? Start recording how long customers take to make a choice as well! (This is why electronic terminals can be useful to collect orders. They can collect all sorts of data to use to generate better responses.)
ChatGPT
Okay, lets jump onto the latest rage, ChatGPT. How does it work? The answers are so amazing, it really does involve the computer having intelligence like a human, right? No. My understanding (with a warning that I am still reading up on it) is it is a predictive model. It is saying “when I have seen these sorts of words, here is the sort of text that other people have written about it, so I can predict the next word to say given what I have said so far”. It’s just been shown sooooo much text about what others have said, it can predict the words people would use in that situation really, really well.
Yes, that is a massive over simplification. The point is still the compute does not “understand” like you or I do. It is using lots of previous content to work out what most probably someone would say if they were asked the question. Pretty darn cool and amazing how good it is, but it’s still “artificial” intelligence. That is, a human looks at the answer and says “I could imagine an intelligent person would write that”, but the computer is really making probabilistic decisions based on previous input to decide what words to return.
One of the problems then is if the data fed to train the computer contains inaccurate or contradictory statements, ChatGPT can return wrong answers. I have asked it for examples explaining an answer to a question, then asked the opposite question and it included some of the same examples to disprove the point! So I find ChatGPT useful to spark ideas and learn about a new space, but I don’t completely trust what it says.
The take way is it still boils down to numbers and probabilities internally. Show it billions of sentences and it can start generating good sentences itself.
Dall-E, MidJourney, Stable diffusion, …
Another very clever use of machine learning has been the generation of images from text. How can it do such a good job of artistry?
Oversimplified again, in a nutshell you take a collection of existing images (and text describing it if you have it) and train a model based on that data. There are techniques like “take the original image, but also zoom in on smaller overlapping sections of the image and process each of them, then try that at different zoom factors” which can be useful to identify different parts of a larger image. Lots and lots of processing. One generative approach I saw then took random noise as an input, then it made probabilistic predictions of what would be a better value for each cell for a very low resolution image. It then used the low resolution image as an input to generate a higher resolution image, upscaling the pixels based on other images it had seen, then repeat again. Lots and lots of processing again. It did not know how to draw a line, but it did know that for cartoon characters you often have black pixels touching each other around the character. Lots of research (by humans) to work out which algorithms worked best, amazing results, but it is copying patterns it has seen in artwork it was trained upon.
Some people do not like these approaches for ethical reasons. Some people are not happy as it may reduce work for real life artists. (I understand the concern, but new technology has changed the landscape many times before – cars made horses less important. I don’t think this argument will stop anything.) Others are not happy because many services have used images without permission from the copyright owners. They can copy the style of another artist by feeding artwork from that artist into the algorithm as training data. Some interesting legal cases lie ahead! Why is it acceptable for a human to study someone else’s artwork, but not a computer? (Personal vague feeling is because machine learning is based on trying to repeat previous creations, with a bit of randomness thrown in. Human artists, excluding forgers(!), are creating something from their own inspiration. The intent is different.)
I am not going to be looking at AI to generate images or videos. I am looking at can I leverage machine learning to help my own development workflow based on my own previous creations, to speed my future work up. If you are interested in generating videos from AI generate images, this is the wrong blog post for you.
How I animate
I create animated cartoons using 3D characters I created in VRoid Studio (free software) and the Sequences package in Unity. I create a new Unity project per location, add various assets to build up the “set” (for example, I bought a “School” 3D model from the Unity Asset Store and then used Unity Terrain to surround it with trees etc), then I use the Sequences package to build up a hierarchy of Timeline objects, one per shot (typically a few seconds long). Characters exist as prefabs in Unity that I drop into shots, as well as prefabs for cameras, the sun, etc.
I better artist may create their own locations, props, and characters. I simply don’t have the time (or interest).
To animate characters I use a mix of animation clips that are available from 3rd parties and custom recordings that I make myself. For example, I tend to use standard idle, sitting, and walk cycles then override the upper body using Unity override tracks (with avatar masks) in an Animation Timeline. I call this “animation on the cheap”. Good animators (like in Pixar etc movies) will create a custom animation per shot to get the most out of every shot. My goal is to create simple cartoons quickly, not A-grade productions. And I am trying to do it with free or inexpensive tools.
As part of reducing effort, I use prefabs, 3rd party animation clips, etc (reusable components) as much as possible to save time. It reduces quality but speeds up the creation process. Yeah, yeah, I then spend all that saved time and more looking at new techniques to save even more time! It’s probably more efficient to just get on and create content. But I like to learn new things too.
Here is an example Timeline for a single shot. There are multiple tracks down the screen. I include clips in tracks (but also custom recordings). For example “Deb” has a base animation of “T-Pose” with an override track for her “Left Hand” of “LH_Hold” (a pose I created which is a hand with fingers curled holding a handle, in this case the steering wheel of a car). I also use custom recordings – the “Override 3” track contains a custom animation of the hands gently moving from side to side as if the steering wheel is moving a little to keep the car on the road.
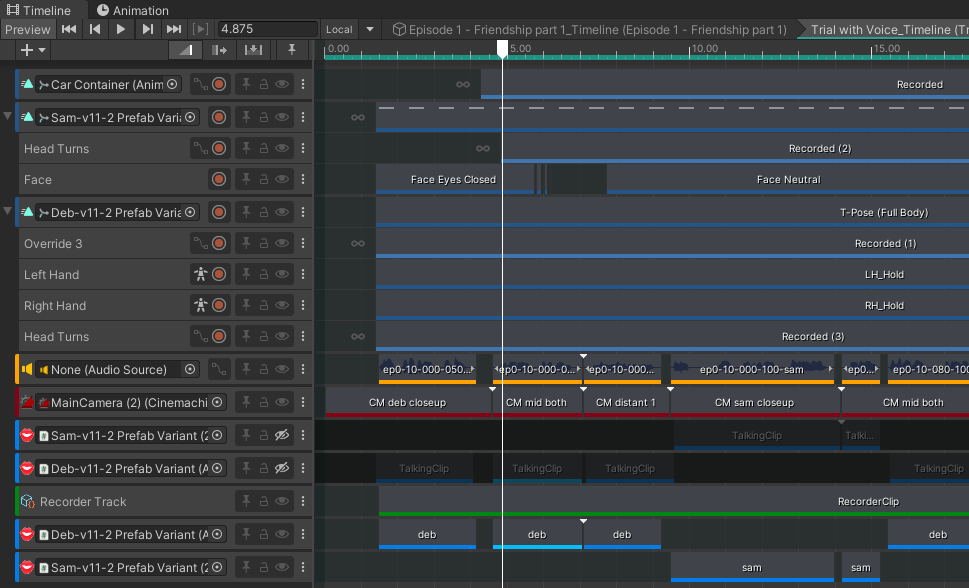
The challenge is can I use artificial intelligence / machine learning to speed up assembly camera shots like the above?
I plan to start with deciding which characters belong in a scene, then can I work out which override tracks a character should have (do I need them to have clenched fists?). Then can I come up with animation clips to add to tracks? Do I need to blend between clips? What is the timing? For custom recordings, can the computer learn what driving means (so it synthesizes similar custom recordings when I need it later).
I don’t know how far I can seriously go with a limited amount of time. I have seen projects where they have used lots of example animations to generate custom sequences from text (like “create an animation clip of someone walking holding their hands above their heads”). Very cool, but probably beyond what I can achieve in my limited time availability. That is an advanced problem. I am going to start with simple challenges and work up to that over time.
Scene Assembly from Text
What I want to do is feed in a screenplay written as directions in text and have the model construct as much of a scene for me as possible. Individual camera shots from my screenplay will be the input; positioning of characters, Timeline contents, animation clips positioning, and so on will be the output. For example, can I just say “Sam is sitting at his desk in the classroom” and it works out where that is from previous episodes I have finished. I am doing a series – I expect a degree of repetition between episodes, more than what you would probably get in a feature length movie.
To do this, I will create a JSON encoding of scene description. I can then have a C# script in Unity to extract information from completed episodes and write it out as JSON to use as training data. I will have another script to read a JSON file and apply it to a shot. The machine learning code then does not have to run inside Unity, making experimentation easier.
Here is a fragment of a screenplay in the format I use. I use a specific syntax (similar in concept to markdown) to encode information into the text. I use Google docs and run a Google docs script to format the text based on these hints. E.g. labels in square brackets at the start of a line start a new camera shot (my script adds bold). A line starting and ending with “-” is taken as a character name with the following lines being dialog. There is more than just this formatting, but it means I can write text in any text editor and pretty up the formatting later to make it easier to read.

Examples of specific tasks I am thinking about for upcoming posts include:
- Can it work out which characters to include in a shot? If so, I can automate the creation of tracks for that character. What if I use phrases like “them” or “the whole class”? Maybe I need to provide previous shots as context.
- Can it recognize animation clips a shot needs from my library and drop them into a Timeline for me. Can it get timing right?
- Can it recognize that Deb is behind the steering wheel of a car with Sam next to her in the passenger seat. The first time it sees such text it won’t know that. But if it happens a number of times in future episodes, will it start to recognize the pattern and position Deb so she is sitting, in a car, with IK controls so her hands are on the steering wheel?
- Getting extreme, can it adjust ISO levels and color gradients so that new shots “look similar” to previous shots without me having to fiddle things? Create the shot, generate an image showing lighting levels, then made adjustments based on the result. Do I need to provide a screenshot for it to make good adjustments, or can it just look at light strengths and shot locations from previous shots and make a good estimate?
Conclusions
Don’t expect a rapid solution in this sub-series of posts. I wanted more hands on experience with machine learning, so decided on this project to learn from. My first step is going to be deciding on the JSON structure for a scene description. Then I am going to tackle a series of simple challenges like identifying which characters should appear in a shot. This can be tricky as I sometimes leave characters out because they are not visible. I may purposely go back to old episodes as well to be more consistent in how I do things, to give it cleaner training data. Maybe introduce some more animation clips such as for eye rolls (currently I recreate it each time).
For me the ultimate dream would be to write a screenplay, then modify scenes using voice commands while inside Unity. I doubt I will ever achieve that, but it might be kinda cool. “Pull back a bit on the camera. Hmmm. Show me 5 different camera angles. Okay, use the third one. Lower the brightness a bit. Lights! Action! Camera! Next shot! Sam, sit in the chair. Turn a bit to the left. Hank, look angry! …”
